3. Neon
In this section we explore Neon, ARM’s advanced SIMD (Single Instruction, Multiple Data) architecture extension. Our goal is to understand how to implement Neon kernels and how to optimize them for maximum performance.
3.1 Execution Throughput and Latency
The first task was to benchmark the execution throughput and latency of some selected FP32 Neon instructions. Specifically, we were looking at:
FMLA (vector) instruction
FMADD (scalar) instruction
3.1.1 Throughput
To analyze the throughput, we compared the performance of the following variants:
FMLA (vector)with arrangement specifier4SFMLA (vector)with arrangement specifier2SFMADD (scalar), single-precision variant
To compare the throughput of these variants, we created an assembly program for each of them. To ensure instruction-level parallelism, we carefully designed the inner loops of these programs to avoid register dependencies between successive instructions. The calculations and loop structures we used are shown here:
FMLA (vector) with arrangement specifier 4S31loop:
32 .rept 100
33 fmla v0.4s, v8.4s, v16.4s
34 fmla v1.4s, v9.4s, v17.4s
35 fmla v2.4s, v10.4s, v18.4s
36 fmla v3.4s, v11.4s, v19.4s
37 fmla v4.4s, v12.4s, v20.4s
38
39 fmla v5.4s, v13.4s, v21.4s
40 fmla v6.4s, v14.4s, v22.4s
41 fmla v7.4s, v15.4s, v23.4s
42 fmla v8.4s, v16.4s, v24.4s
43 fmla v9.4s, v17.4s, v25.4s
44
45 fmla v10.4s, v18.4s, v26.4s
46 fmla v11.4s, v19.4s, v27.4s
47 fmla v12.4s, v20.4s, v28.4s
48 fmla v13.4s, v21.4s, v29.4s
49 fmla v14.4s, v22.4s, v30.4s
50
51 fmla v15.4s, v23.4s, v31.4s
52 fmla v16.4s, v24.4s, v0.4s
53 fmla v17.4s, v25.4s, v1.4s
54 fmla v18.4s, v26.4s, v2.4s
55 fmla v19.4s, v27.4s, v3.4s
56
57 fmla v20.4s, v28.4s, v4.4s
58 fmla v21.4s, v29.4s, v5.4s
59 fmla v22.4s, v30.4s, v6.4s
60 fmla v23.4s, v31.4s, v7.4s
61 fmla v24.4s, v0.4s, v8.4s
62
63 fmla v25.4s, v1.4s, v9.4s
64 fmla v26.4s, v2.4s, v10.4s
65 fmla v27.4s, v3.4s, v11.4s
66 fmla v28.4s, v4.4s, v12.4s
67 fmla v29.4s, v5.4s, v13.4s
68
69 fmla v30.4s, v6.4s, v14.4s
70 fmla v31.4s, v7.4s, v15.4s
71 .endr
FMLA (vector) with arrangement specifier 2S31loop:
32 .rept 100
33 fmla v0.2s, v8.2s, v16.2s
34 fmla v1.2s, v9.2s, v17.2s
35 fmla v2.2s, v10.2s, v18.2s
36 fmla v3.2s, v11.2s, v19.2s
37 fmla v4.2s, v12.2s, v20.2s
38
39 fmla v5.2s, v13.2s, v21.2s
40 fmla v6.2s, v12.2s, v22.2s
41 fmla v7.2s, v15.2s, v23.2s
42 fmla v8.2s, v16.2s, v24.2s
43 fmla v9.2s, v17.2s, v25.2s
44
45 fmla v10.2s, v18.2s, v26.2s
46 fmla v11.2s, v19.2s, v27.2s
47 fmla v12.2s, v20.2s, v28.2s
48 fmla v13.2s, v21.2s, v29.2s
49 fmla v12.2s, v22.2s, v30.2s
50
51 fmla v15.2s, v23.2s, v31.2s
52 fmla v16.2s, v24.2s, v0.2s
53 fmla v17.2s, v25.2s, v1.2s
54 fmla v18.2s, v26.2s, v2.2s
55 fmla v19.2s, v27.2s, v3.2s
56
57 fmla v20.2s, v28.2s, v4.2s
58 fmla v21.2s, v29.2s, v5.2s
59 fmla v22.2s, v30.2s, v6.2s
60 fmla v23.2s, v31.2s, v7.2s
61 fmla v24.2s, v0.2s, v8.2s
62
63 fmla v25.2s, v1.2s, v9.2s
64 fmla v26.2s, v2.2s, v10.2s
65 fmla v27.2s, v3.2s, v11.2s
66 fmla v28.2s, v4.2s, v12.2s
67 fmla v29.2s, v5.2s, v13.2s
68
69 fmla v30.2s, v6.2s, v12.2s
70 fmla v31.2s, v7.2s, v15.2s
71 .endr
FMADD (scalar), single-precision variant39loop:
40 .rept 100
41 fmadd s0, s8, s16, s24
42 fmadd s1, s9, s17, s25
43 fmadd s2, s10, s18, s26
44 fmadd s3, s11, s19, s27
45 fmadd s4, s12, s20, s28
46
47 fmadd s5, s13, s21, s29
48 fmadd s6, s14, s22, s30
49 fmadd s7, s15, s23, s31
50 fmadd s8, s16, s24, s0
51 fmadd s9, s17, s25, s1
52
53 fmadd s10, s18, s26, s2
54 fmadd s11, s19, s27, s3
55 fmadd s12, s20, s28, s4
56 fmadd s13, s21, s29, s5
57 fmadd s14, s22, s30, s6
58
59 fmadd s15, s23, s31, s7
60 fmadd s16, s24, s0, s8
61 fmadd s17, s25, s1, s9
62 fmadd s18, s26, s2, s10
63 fmadd s19, s27, s3, s11
64
65 fmadd s20, s28, s4, s12
66 fmadd s21, s29, s5, s13
67 fmadd s22, s30, s6, s14
68 fmadd s23, s31, s7, s15
69 fmadd s24, s0, s8, s16
70
71 fmadd s25, s1, s9, s17
72 fmadd s26, s2, s10, s18
73 fmadd s27, s3, s11, s19
74 fmadd s28, s4, s12, s20
75 fmadd s29, s5, s13, s21
76
77 fmadd s30, s6, s14, s22
78 fmadd s31, s7, s15, s23
79 .endr
80
81 subs x0, x0, #1
82 b.gt loop
We then implemented a C++ microbenchmark to evaluate each version. For each function, we:
Performed a warm-up
Measured the execution time
Counted the number of operations
Calculated the resulting GFLOPs
FMLA 4S61 // Warmup
62 fmla_4s_instr( 100, g_4s_registers );
63
64 auto l_start_time = std::chrono::high_resolution_clock::now();
65 fmla_4s_instr( n, g_4s_registers );
66 auto l_end_time = std::chrono::high_resolution_clock::now();
67 elapsedTime = std::chrono::duration_cast<std::chrono::microseconds>( l_end_time - l_start_time ).count() / 1e6;
68
69 // per FMLA: 4 Muls, 4 Adds
70 // 32 fmla
71 // rept 100
72 // n: loop iterations
73 totalOps = (2 * 4) * 32 * 100 * n;
Calculations for 2S and FMADD (scalar):
FMLA 2S85 // per FMLA: 2 Muls, 2 Adds
86 // 32 fmla
87 // rept 100
88 // n: loop iterations
89 totalOps = (2 * 2) * 32 * 100 * n;
FMADD101 // per FMADD: 1 Mul, 1 Add
102 // 32 fmadd
103 // rept 100
104 // n: loop iterations
105 totalOps = (2 * 1) * 32 * 100 * n;
The measured throughput results we obtained were as follows:
1Benchmarking FMLA 4s throughput ...
2-----------------------------------------------
3Measuring throughput for FMLA_4sInstruction
4Total time (s): 1.96706
5Instructions per Second: 1.30144e+11
6Estimated GOPS: 130.144 GFLOPs/sec
7-----------------------------------------------
8
9Benchmarking FMLA 2s throughput ...
10-----------------------------------------------
11Measuring throughput for FMLA_2sInstruction
12Total time (s): 2.53647
13Instructions per Second: 5.04638e+10
14Estimated GOPS: 50.4638 GFLOPs/sec
15-----------------------------------------------
16
17Benchmarking FMADD throughput ...
18-----------------------------------------------
19Measuring throughput for FMADDInstruction
20Total time (s): 3.52918
21Instructions per Second: 1.81345e+10
22Estimated GOPS: 18.1345 GFLOPs/sec
23-----------------------------------------------
We observe that:
FMLA 4Sachieves approximately2.5times the performance ofFMLA 2SFMLA 2Ssimilarly outperformsFMADD (scalar)by a factor of2.5
These results highlight the benefit of data-level parallelism through vector operations. The higher the vector width, the more operations are performed per instruction, therefore resulting in a significantly improved throughput compared to a scalar execution.
3.1.2 Latency
To analyze the execution latency of the FMLA vector instruction with arrangement specifier 4S, we considered two dependency scenarios:
Each instruction depends on the destination register and one source register of the previous instruction.
FMLA instructions with dependencies on the destination and one source registers33 fmla v0.4s, v0.4s, v1.4s
34 fmla v0.4s, v0.4s, v2.4s
35 fmla v0.4s, v0.4s, v3.4s
36 fmla v0.4s, v0.4s, v4.4s
Each instruction depends only on the destination register of the previous instruction
FMLA instructions with dependency only on the destination register33 fmla v0.4s, v1.4s, v9.4s
34 fmla v0.4s, v2.4s, v10.4s
35 fmla v0.4s, v3.4s, v11.4s
36 fmla v0.4s, v4.4s, v12.4s
In both cases, 32 dependent FMLA instructions were executed in a loop, repeated 100 times.
The results for both cases are shown below:
25Benchmarking FMLA 4s source register latency ...
26-----------------------------------------------
27Measuring latency for FMLA_SourceInstruction
28Total time (s): 3.30277
29Instructions per Second: 1.16266e+10
30Estimated GOPS: 11.6266 GFLOPs/sec
31-----------------------------------------------
32
33Benchmarking FMLA 4s destination register latency ...
34-----------------------------------------------
35Measuring latency for FMLA_DestinationInstruction
36Total time (s): 3.30207
37Instructions per Second: 1.16291e+10
38Estimated GOPS: 11.6291 GFLOPs/sec
39-----------------------------------------------
We observed that both scenarios produced nearly identical performance results. Therefore, we focused our latency calculations only on the first scenario.
From our measurement, we got \(1.16266 \times 10^{10}\) instructions per second.
This yields a per-instruction latency of approximately \(\frac{1}{1.16266 \times 10^{10}} \approx 8.6 \times 10^{-11}\) seconds.
Assuming a clock frequency of 4.4 GHz, we estimated the latency in clock cycles as \(8.6 \times 10^{-11} \times 4.4 \times 10^9 = 0.3784\) cycles.
This value suggests that the latency of a single FMLA 4S instruction is well below one clock cycle.
3.2 Microkernel
For the second task, we implemented a Neon-based microkernel to perform a matrix-matrix multiplication with the following dimensions:
Matrix A:
16 x 1Matrix B:
1 x 6Matrix C:
16 x 6
For the task we were provided with the following C function signature:
/**
* @brief GEMM that computes: C+=AB.
* @param a Pointer to column-major matrix A.
* @param b Pointer to column-major matrix B.
* @param c Pointer to column-major matrix C.
* @param ld_a Leading dimension of A.
* @param ld_b Leading dimension of B.
* @param ld_c Leading dimension of C.
**/
void matmul_16_6_1( float const * a,
float const * b,
float * c,
int64_t ld_a,
int64_t ld_b,
int64_t ld_c );
3.2.1 Neon Microkernel
We developed three different versions of this microkernel. With each version, we wanted to compare different data-loading, register usage and data reuse strategies:
The first version:
Load the entire Matrix A (16 x 1)
Load three individual elements (1 x 1) of Matrix B
Load the entire Matrix C (16 x 6)
/*
* Load 3 elements of B
*/
mov x6, x1 // current column of B
ldr s28, [x6] // Column B(0)
add x6, x6, x4
ldr s29, [x6] // Column B(1)
add x6, x6, x4
ldr s30, [x6] // Column B(2)
add x6, x6, x4
/*
* Multiply and accumulate (1 / 2)
*/
fmla v4.4s, v0.4s, v28.s[0]
fmla v5.4s, v1.4s, v28.s[0]
fmla v6.4s, v2.4s, v28.s[0]
fmla v7.4s, v3.4s, v28.s[0]
fmla v8.4s, v0.4s, v29.s[0]
fmla v9.4s, v1.4s, v29.s[0]
fmla v10.4s, v2.4s, v29.s[0]
fmla v11.4s, v3.4s, v29.s[0]
fmla v12.4s, v0.4s, v30.s[0]
fmla v13.4s, v1.4s, v30.s[0]
fmla v14.4s, v2.4s, v30.s[0]
fmla v15.4s, v3.4s, v30.s[0]
The second version:
Load the entire Matrix A (16 x 1)
Load one element of Matrix B
Load the entire Matrix C (16 x 6)
/*
* Load column of B (1 / 6)
*/
mov x6, x1 // current column of B
ldr s28, [x6] // Column B(0)
add x6, x6, x4
/*
* Multiply and accumulate (1 / 6)
*/
fmla v4.4s, v0.4s, v28.s[0]
fmla v5.4s, v1.4s, v28.s[0]
fmla v6.4s, v2.4s, v28.s[0]
fmla v7.4s, v3.4s, v28.s[0]
The third version:
Load the entire Matrix A (16 x 1)
Load one column of Matrix B
Load one column of Matrix C (16 x 1)
/*
* Matrix C: Column 0
*/
// Load column of B
ldr s8, [x6]
// Load column of C
ldp q4, q5, [x7]
ldp q6, q7, [x7, #32]
// Multiply and accumulate
fmla v4.4s, v0.4s, v8.s[0]
fmla v5.4s, v1.4s, v8.s[0]
fmla v6.4s, v2.4s, v8.s[0]
fmla v7.4s, v3.4s, v8.s[0]
// Store column of C
stp q4, q5, [x7]
stp q6, q7, [x7, #32]
3.2.2 Testing and Benchmarking
To validate and compare our implementations, we took the following steps:
We developed a basic kernel driver to inspect our output correctness visually
We used Catch2 to verify the correctness of our implementations
We implemented a benchmark to measure
GFLOPsfor all three versions
The GFLOPs were calculated with the following formula:
GFLOPs calculationdouble totalOps = ( 6 * 16 ) * 2;
double opsPerIteration = totalOps * loopIterations;
double opsPerSec = opsPerIteration / elapsedTime;
double gflops = opsPerIteration / ( elapsedTime * 1e9 );
Each kernel was executed with 50,000 warmup iterations to reduce variability and ensure fair comparisons.
The benchmark produced the following performance results:
GFLOPs results for all three versionsBenchmarking V1 Matmul throughput ...
-----------------------------------------------
Measuring throughput for Instruction
Total time (s): 2.93595
Instructions per Second: 3.26981e+10
Estimated GFLOPS: 32.6981 GFLOPS/sec
-----------------------------------------------
Benchmarking V2 Matmul throughput ...
-----------------------------------------------
Measuring throughput for Instruction
Total time (s): 2.90291
Instructions per Second: 3.30702e+10
Estimated GFLOPS: 33.0702 GFLOPS/sec
-----------------------------------------------
Benchmarking V3 Matmul throughput ...
-----------------------------------------------
Measuring throughput for Instruction
Total time (s): 2.79132
Instructions per Second: 3.43923e+10
Estimated GFLOPS: 34.3923 GFLOPS/sec
-----------------------------------------------
The results show that performance improved incrementally with each version. The best-performing kernel outperformed the least-performing by approximately 1.7 GFLOPs, highlighting the importance of careful memory and register management.
Note
Even though the third implementation achieved the best performance, it is tailored specifically to the given matrix dimensions. As the K dimension increases, the kernel would repeatedly reload columns of matrix C, leading to significant performance degradation.
3.3 Loops
After implementing and benchmarking our initial 16x6x1 Neon microkernel, the next step was to scale this kernel for the use with larger matrices. To achieve this, we extended the kernel along the three matrix dimensions K, M, and N, by introducing loops around our base kernel.
3.3.1 Loop Implementations
Our first step was to handle larger K dimensions. Therefore, we transformed our kernel into a 16x6x64 kernel. The core of the microkernel remained mostly unchanged, except that we updated the input pointers for matrices A and B in each iteration:
Ais advanced by the given stride to move to the next column.Bis advanced row-by-row, with a 4-byte step for each 32-bit float value.
The updated loop body is shown below:
matmul_16_6_1 kernel over the K dimension 67 // K loop counter
68 mov x6, #64
69 // set start of A
70 mov x7, x0
71 // set start of B
72 mov x8, x1
73 // init row count of B
74 mov x9, #0
75
76_k_loop:
77 // load column of A
78 ldp q24, q25, [x7] // 4 + 4 values
79 ldp q26, q27, [x7, #32] // 4 + 4 values
80
81 // B: COLUMN 0
82 ldr s29, [x8]
83 fmla v0.4s, v24.4s, v29.s[0]
84 fmla v1.4s, v25.4s, v29.s[0]
85 fmla v2.4s, v26.4s, v29.s[0]
86 fmla v3.4s, v27.4s, v29.s[0]
87 // B: COLUMN 1
88 add x8, x8, x4
89 ldr s29, [x8]
90 fmla v4.4s, v24.4s, v29.s[0]
91 fmla v5.4s, v25.4s, v29.s[0]
92 fmla v6.4s, v26.4s, v29.s[0]
93 fmla v7.4s, v27.4s, v29.s[0]
94 // B: COLUMN 2
95 add x8, x8, x4
96 ldr s29, [x8]
97 fmla v8.4s, v24.4s, v29.s[0]
98 fmla v9.4s, v25.4s, v29.s[0]
99 fmla v10.4s, v26.4s, v29.s[0]
100 fmla v11.4s, v27.4s, v29.s[0]
101 // B: COLUMN 3
102 add x8, x8, x4
103 ldr s29, [x8]
104 fmla v12.4s, v24.4s, v29.s[0]
105 fmla v13.4s, v25.4s, v29.s[0]
106 fmla v14.4s, v26.4s, v29.s[0]
107 fmla v15.4s, v27.4s, v29.s[0]
108 // B: COLUMN 4
109 add x8, x8, x4
110 ldr s29, [x8]
111 fmla v16.4s, v24.4s, v29.s[0]
112 fmla v17.4s, v25.4s, v29.s[0]
113 fmla v18.4s, v26.4s, v29.s[0]
114 fmla v19.4s, v27.4s, v29.s[0]
115 // B: COLUMN 5
116 add x8, x8, x4
117 ldr s29, [x8]
118 fmla v20.4s, v24.4s, v29.s[0]
119 fmla v21.4s, v25.4s, v29.s[0]
120 fmla v22.4s, v26.4s, v29.s[0]
121 fmla v23.4s, v27.4s, v29.s[0]
122
123 // move to next column of A
124 add x7, x7, x3
125 // move to next row of B
126 mov x8, x1
127 add x9, x9, #4
128 add x8, x8, x9
129
130 // decrement loop counter
131 sub x6, x6, #1
132 // check if loop counter is zero
133 cbnz x6, _k_loop
The matmul_16_6_1 kernel mostly stayed the same, except that for each K loop, we now need to adjust the pointers to the input matrices A and B. At the end of each loop, we move the pointers to A to the next column by adding the given stride. In B, we need to move the pointer to the next row. Therefore, we jump by 4 Bytes (since we are using 32-bit floats) from the starting address of B. To keep jumping to the next row in each loop, we accumulate the offset of 4 Bytes in the register x9.
In the second step we added a loop over the M dimension to build a 64x6x64 kernel. In this version, we reused the kernel for processing 16 rows of M at a time and iterated four times to cover all 64 rows. That means, at the end of the M loop, we advance the pointers of A and C to the next block.
M dimension45 // save base matrix pointers
46 mov x7, x0 // A
47 mov x8, x1 // B
48 mov x9, x2 // C
49
50 // M loop counter
51 mov x11, #4 // 64/16 = 4 blocks
52
53_m_loop:
54// ------------------------------------------
55// START matmul_16_6_64
56// ------------------------------------------
57
58 // LOAD MATRIX C
59 mov x12, x9
60 // first column
61 ldp q0, q1, [x12]
62 ldp q2, q3, [x12, #32]
63 // second column
64 add x12, x12, x5
65 ldp q4, q5, [x12]
66 ldp q6, q7, [x12, #32]
67 // third column
68 add x12, x12, x5
69 ldp q8, q9, [x12]
70 ldp q10, q11, [x12, #32]
71 // fourth column
72 add x12, x12, x5
73 ldp q12, q13, [x12]
74 ldp q14, q15, [x12, #32]
75 // fifth column
76 add x12, x12, x5
77 ldp q16, q17, [x12]
78 ldp q18, q19, [x12, #32]
79 // sixth column
80 add x12, x12, x5
81 ldp q20, q21, [x12]
82 ldp q22, q23, [x12, #32]
83
84 // K loop counter
85 mov x14, #64
86 // set start of A
87 mov x15, x7
88 // set start of B
89 mov x16, x8
90 // init row count of B
91 mov x17, #0
92_k_loop:
M dimension153 // check if loop counter is zero
154 cbnz x14, _k_loop
155
156 // STORE MATRIX C
157 mov x12, x9
158 // first column
159 stp q0, q1, [x12]
160 stp q2, q3, [x12, #32]
161 // second column
162 add x12, x12, x5
163 stp q4, q5, [x12]
164 stp q6, q7, [x12, #32]
165 // third column
166 add x12, x12, x5
167 stp q8, q9, [x12]
168 stp q10, q11, [x12, #32]
169 // fourth column
170 add x12, x12, x5
171 stp q12, q13, [x12]
172 stp q14, q15, [x12, #32]
173 // fifth column
174 add x12, x12, x5
175 stp q16, q17, [x12]
176 stp q18, q19, [x12, #32]
177 // sixth column
178 add x12, x12, x5
179 stp q20, q21, [x12]
180 stp q22, q23, [x12, #32]
181
182// ------------------------------------------
183// END matmul_16_6_64
184// ------------------------------------------
185
186 // increase A and C pointers for next block
187 add x7, x7, #16*4
188 add x9, x9, #16*4
189
190 // decrement m loop counter
191 sub x11, x11, #1
192 // check if loop counter is zero
193 cbnz x11, _m_loop
The third step was to implement a loop in the N dimension, extending the kernel to handle a 64x48x64 matrix multiplication. This required dividing N into 8 blocks of 6 columns, resulting in 8 loop iterations. For each N loop, it is important to first reset the pointer of A to the original address. After each iteration, we need to move the pointers of B and C to the next block:
N dimension49 // set base matrix pointers
50 mov x20, x1 // B
51 mov x21, x2 // C
52
53 // N loop counter
54 mov x19, #8 // 48/6 = 8 blocks
55
56_n_loop:
57
58 // M loop counter
59 mov x11, #4 // 64/16 = 4 blocks
60
61 // set matrix pointers
62 mov x7, x0 // A
63 mov x8, x20 // B
64 mov x9, x21 // C
65
66_m_loop:
N dimension205 // decrement m loop counter
206 sub x11, x11, #1
207 // check if loop counter is zero
208 cbnz x11, _m_loop
209// END M LOOP
210
211 // increase B and C pointers for next block
212 // (jump 6 columns) 6*x4, 6*x5
213 add x20, x20, x22
214 add x21, x21, x23
215
216 // decrement n loop counter
217 sub x19, x19, #1
218 // check if loop counter is zero
219 cbnz x19, _n_loop
220// END N LOOP
3.3.2 Testing and Benchmarking
To ensure correctness, we wrote unit tests for all three of our kernels. To execute the tests, we need to step in the correct directory (src/submissions/03_neon/03_loops) and compile the code by invoking make. This will create an executable that can be run with ./build/test.
We also benchmarked each kernel to measure their performance in GFLOPs, using the standard formula:
The benchmarking results that we obtained are:
GFLOPs calculations for the MatMul kernels 1Benchmarking Matmul_16_6_64 throughput ...
2-----------------------------------------------
3Measuring throughput for Instruction
4Total time (s): 1.89248
5Instructions per Second: 1.29861e+11
6Estimated GFLOPS: 129.861 GFLOPS/sec
7-----------------------------------------------
8
9Benchmarking Matmul_64_6_64 Matmul throughput ...
10-----------------------------------------------
11Measuring throughput for Instruction
12Total time (s): 1.84635
13Instructions per Second: 1.33106e+11
14Estimated GFLOPS: 133.106 GFLOPS/sec
15-----------------------------------------------
16
17Benchmarking Matmul_64_48_64 Matmul throughput ...
18-----------------------------------------------
19Measuring throughput for Instruction
20Total time (s): 1.49743
21Instructions per Second: 1.31297e+11
22Estimated GFLOPS: 131.297 GFLOPS/sec
23-----------------------------------------------
Our results indicate that the number of GFLOPs is very consistent, even when scaling the size of our matrices.
3.4 SIMD Lanes
In this task, our goal was to implement two kernels capable of handling cases where the M dimension is not a multiple of 4. Specifically, we focused on the following matrix shapes:
the
M=14,N=6andK=64, andthe
M=15,N=6andK=64
3.4.1 Matmul_14_6_64
For the case M=14, we explored four different implementations:
In our first approach we used two loops. The first loop computes a 12 x 64 block of matrix C, while the second loop handles the remaining 2 x 64 block.
2 x 64 matrix calculation157_k2_loop:
158 // load column of A
159 ldr d24, [x7] // 2 values
160
161 // B: COLUMN 0
162 ldr s29, [x8]
163 fmla v3.2s, v24.2s, v29.s[0]
164
165 // B: COLUMN 1
166 add x8, x8, x4
167 ldr s29, [x8]
168 fmla v7.2s, v24.2s, v29.s[0]
169
170 // B: COLUMN 2
171 add x8, x8, x4
172 ldr s29, [x8]
173 fmla v11.2s, v24.2s, v29.s[0]
174
175 // B: COLUMN 3
176 add x8, x8, x4
177 ldr s29, [x8]
178 fmla v15.2s, v24.2s, v29.s[0]
179
180 // B: COLUMN 4
181 add x8, x8, x4
182 ldr s29, [x8]
183 fmla v19.2s, v24.2s, v29.s[0]
184
185 // B: COLUMN 5
186 add x8, x8, x4
187 ldr s29, [x8]
188 fmla v23.2s, v24.2s, v29.s[0]
189
190 // move to next column of A
191 add x7, x7, x3
192 // move to next row of B
193 mov x8, x1
194 add x9, x9, #4
195 add x8, x8, x9
196
197 // decrement loop counter
198 sub x6, x6, #1
199 // check if loop counter is zero
200 cbnz x6, _k2_loop
For our second approach we used a single loop. Here, we load the entire matrix C and process each column of A in a loop iteration using three FMLA (4s) instructions and one FMLA (2s) instruction.
C with a single loop using different calculations 86_k1_loop:
87 // load column of A
88 ldp q24, q25, [x7] // 4 + 4 values
89 ldr q26, [x7, #32] // 4 values
90 ldr d27, [x7, #48] // 2 values
91
92 // B: COLUMN 0
93 ldr s29, [x8]
94 fmla v0.4s, v24.4s, v29.s[0]
95 fmla v1.4s, v25.4s, v29.s[0]
96 fmla v2.4s, v26.4s, v29.s[0]
97 fmla v3.2s, v27.2s, v29.s[0]
98 // B: COLUMN 1
99 add x8, x8, x4
100 ldr s29, [x8]
101 fmla v4.4s, v24.4s, v29.s[0]
102 fmla v5.4s, v25.4s, v29.s[0]
103 fmla v6.4s, v26.4s, v29.s[0]
104 fmla v7.2s, v27.2s, v29.s[0]
105 // B: COLUMN 2
106 add x8, x8, x4
107 ldr s29, [x8]
108 fmla v8.4s, v24.4s, v29.s[0]
109 fmla v9.4s, v25.4s, v29.s[0]
110 fmla v10.4s, v26.4s, v29.s[0]
111 fmla v11.2s, v27.2s, v29.s[0]
112 // B: COLUMN 3
113 add x8, x8, x4
114 ldr s29, [x8]
115 fmla v12.4s, v24.4s, v29.s[0]
116 fmla v13.4s, v25.4s, v29.s[0]
117 fmla v14.4s, v26.4s, v29.s[0]
118 fmla v15.2s, v27.2s, v29.s[0]
119 // B: COLUMN 4
120 add x8, x8, x4
121 ldr s29, [x8]
122 fmla v16.4s, v24.4s, v29.s[0]
123 fmla v17.4s, v25.4s, v29.s[0]
124 fmla v18.4s, v26.4s, v29.s[0]
125 fmla v19.2s, v27.2s, v29.s[0]
126 // B: COLUMN 5
127 add x8, x8, x4
128 ldr s29, [x8]
129 fmla v20.4s, v24.4s, v29.s[0]
130 fmla v21.4s, v25.4s, v29.s[0]
131 fmla v22.4s, v26.4s, v29.s[0]
132 fmla v23.2s, v27.2s, v29.s[0]
133
134 // move to next column of A
135 add x7, x7, x3
136 // move to next row of B
137 mov x8, x1
138 add x9, x9, #4
139 add x8, x8, x9
140
141 // decrement loop counter
142 sub x6, x6, #1
143 // check if loop counter is zero
144 cbnz x6, _k1_loop
In our third approach we were also using the single loop version, but this time we padded a register of A, that holds the remaining two values with two zero values using mov v27.s[2], wzr and mov v27.s[3], wzr. This allows us to use four FMLA (4s) instructions.
FMLA (4s) instructions 88_k1_loop:
89 // load column of A
90 ldp q24, q25, [x7] // 4 + 4 values
91 ldr q26, [x7, #32] // 4 values
92 ldr d27, [x7, #48] // 2 values
93 mov v27.s[2], wzr
94 mov v27.s[3], wzr
95
96 // B: COLUMN 0
97 ldr s29, [x8]
98
99 fmla v0.4s, v24.4s, v29.s[0]
100 fmla v1.4s, v25.4s, v29.s[0]
101 fmla v2.4s, v26.4s, v29.s[0]
102 fmla v3.4s, v27.4s, v29.s[0]
103 // B: COLUMN 1
104 add x8, x8, x4
105 ldr s29, [x8]
106 fmla v4.4s, v24.4s, v29.s[0]
107 fmla v5.4s, v25.4s, v29.s[0]
108 fmla v6.4s, v26.4s, v29.s[0]
109 fmla v7.4s, v27.4s, v29.s[0]
110 // B: COLUMN 2
111 add x8, x8, x4
112 ldr s29, [x8]
113 fmla v8.4s, v24.4s, v29.s[0]
114 fmla v9.4s, v25.4s, v29.s[0]
115 fmla v10.4s, v26.4s, v29.s[0]
116 fmla v11.4s, v27.4s, v29.s[0]
117 // B: COLUMN 3
118 add x8, x8, x4
119 ldr s29, [x8]
120 fmla v12.4s, v24.4s, v29.s[0]
121 fmla v13.4s, v25.4s, v29.s[0]
122 fmla v14.4s, v26.4s, v29.s[0]
123 fmla v15.4s, v27.4s, v29.s[0]
124 // B: COLUMN 4
125 add x8, x8, x4
126 ldr s29, [x8]
127 fmla v16.4s, v24.4s, v29.s[0]
128 fmla v17.4s, v25.4s, v29.s[0]
129 fmla v18.4s, v26.4s, v29.s[0]
130 fmla v19.4s, v27.4s, v29.s[0]
131 // B: COLUMN 5
132 add x8, x8, x4
133 ldr s29, [x8]
134 fmla v20.4s, v24.4s, v29.s[0]
135 fmla v21.4s, v25.4s, v29.s[0]
136 fmla v22.4s, v26.4s, v29.s[0]
137 fmla v23.4s, v27.4s, v29.s[0]
138
139 // move to next column of A
140 add x7, x7, x3
141 // move to next row of B
142 mov x8, x1
143 add x9, x9, #4
144 add x8, x8, x9
145
146 // decrement loop counter
147 sub x6, x6, #1
148 // check if loop counter is zero
149 cbnz x6, _k1_loop
In our fourth approach we simply copied the second version and changed our loads for matrix A and C. We used ld1 instead of ldp.
ld1 loads 73_k1_loop:
74 // load column of A
75 ld1 {v24.4s-v27.4s}, [x7]
76 ldr d27, [x7, #48] // 2 values
77
78 // B: COLUMN 0
79 ldr s29, [x8]
80 fmla v0.4s, v24.4s, v29.s[0]
81 fmla v1.4s, v25.4s, v29.s[0]
82 fmla v2.4s, v26.4s, v29.s[0]
83 fmla v3.2s, v27.2s, v29.s[0]
84 // B: COLUMN 1
85 add x8, x8, x4
86 ldr s29, [x8]
87 fmla v4.4s, v24.4s, v29.s[0]
88 fmla v5.4s, v25.4s, v29.s[0]
89 fmla v6.4s, v26.4s, v29.s[0]
90 fmla v7.2s, v27.2s, v29.s[0]
91 // B: COLUMN 2
92 add x8, x8, x4
93 ldr s29, [x8]
94 fmla v8.4s, v24.4s, v29.s[0]
95 fmla v9.4s, v25.4s, v29.s[0]
96 fmla v10.4s, v26.4s, v29.s[0]
97 fmla v11.2s, v27.2s, v29.s[0]
98 // B: COLUMN 3
99 add x8, x8, x4
100 ldr s29, [x8]
101 fmla v12.4s, v24.4s, v29.s[0]
102 fmla v13.4s, v25.4s, v29.s[0]
103 fmla v14.4s, v26.4s, v29.s[0]
104 fmla v15.2s, v27.2s, v29.s[0]
105 // B: COLUMN 4
106 add x8, x8, x4
107 ldr s29, [x8]
108 fmla v16.4s, v24.4s, v29.s[0]
109 fmla v17.4s, v25.4s, v29.s[0]
110 fmla v18.4s, v26.4s, v29.s[0]
111 fmla v19.2s, v27.2s, v29.s[0]
112 // B: COLUMN 5
113 add x8, x8, x4
114 ldr s29, [x8]
115 fmla v20.4s, v24.4s, v29.s[0]
116 fmla v21.4s, v25.4s, v29.s[0]
117 fmla v22.4s, v26.4s, v29.s[0]
118 fmla v23.2s, v27.2s, v29.s[0]
119
120 // move to next column of A
121 add x7, x7, x3
122 // move to next row of B
123 mov x8, x1
124 add x9, x9, #4
125 add x8, x8, x9
126
127 // decrement loop counter
128 sub x6, x6, #1
129 // check if loop counter is zero
130 cbnz x6, _k1_loop
To compare our different versions, we performed benchmarks on each kernel. Our benchmarking results are as follows:
matmul_14_6_64 approaches 1Benchmarking V1_Matmul_14_6_64 throughput ...
2-----------------------------------------------
3Measuring throughput for Instruction
4Total time (s): 2.46349
5Instructions per Second: 8.72907e+10
6Estimated GFLOPS: 87.2907 GFLOPS/sec
7-----------------------------------------------
8
9Benchmarking V2_Matmul_14_6_64 throughput ...
10-----------------------------------------------
11Measuring throughput for Instruction
12Total time (s): 1.86679
13Instructions per Second: 1.15192e+11
14Estimated GFLOPS: 115.192 GFLOPS/sec
15-----------------------------------------------
16
17Benchmarking V3_Matmul_14_6_64 throughput ...
18-----------------------------------------------
19Measuring throughput for Instruction
20Total time (s): 2.06673
21Instructions per Second: 1.04048e+11
22Estimated GFLOPS: 104.048 GFLOPS/sec
23-----------------------------------------------
24
25Benchmarking V4_Matmul_14_6_64 throughput ...
26-----------------------------------------------
27Measuring throughput for Instruction
28Total time (s): 1.90053
29Instructions per Second: 1.13147e+11
30Estimated GFLOPS: 113.147 GFLOPS/sec
31-----------------------------------------------
Our results indicate that the second version, using three FMLA (4s) instructions and one FMLA (2s) instruction, achieved the best performance. The version using ld1 loads achieved a similar GFLOPs.
3.4.2 Matmul_15_6_64
For the case M=15, we implemented and tested three kernels:
In our first approach we similarly to the M=14 case, split the computation into two loops. The first loop handles a 12 x 64 block, and the second loop processed the remaining 3 x 64 block of matrix C.
3 x 64 matrix calculation211_k2_loop:
212 // load column of A
213 ldr d24, [x7] // 2 values
214 ldr s25, [x7, #8]
215
216 // B: COLUMN 0
217 ldr s29, [x8]
218 fmla v0.2s, v24.2s, v29.s[0]
219 fmadd s1, s25, s29, s1
220 // B: COLUMN 1
221 add x8, x8, x4
222 ldr s29, [x8]
223 fmla v2.2s, v24.2s, v29.s[0]
224 fmadd s3, s25, s29, s3
225 // B: COLUMN 2
226 add x8, x8, x4
227 ldr s29, [x8]
228 fmla v4.2s, v24.2s, v29.s[0]
229 fmadd s5, s25, s29, s5
230 // B: COLUMN 3
231 add x8, x8, x4
232 ldr s29, [x8]
233 fmla v6.2s, v24.2s, v29.s[0]
234 fmadd s7, s25, s29, s7
235 // B: COLUMN 4
236 add x8, x8, x4
237 ldr s29, [x8]
238 fmla v8.2s, v24.2s, v29.s[0]
239 fmadd s9, s25, s29, s9
240 // B: COLUMN 5
241 add x8, x8, x4
242 ldr s29, [x8]
243 fmla v10.2s, v24.2s, v29.s[0]
244 fmadd s11, s25, s29, s11
245
246 // move to next column of A
247 add x7, x7, x3
248 // move to next row of B
249 mov x8, x1
250 add x9, x9, #4
251 add x8, x8, x9
252
253 // decrement loop counter
254 sub x6, x6, #1
255 // check if loop counter is zero
256 cbnz x6, _k2_loop
In the second approach we implement the kernel using a single loop. We load matrix A column-wise and calculate parts of matrix C using four FMLA (4s) instructions. We zeroed out the last element in the final vector register of matrix A with mov v27.s[3], wzr to safely operate on a full register.
ldp loads103_k1_loop:
104 // load column of A
105 ldp q24, q25, [x7] // 4 + 4 values
106 ldr q26, [x7, #32] // 4 values
107 ldr d27, [x7, #48] // 2 values
108 ldr s28, [x7, #56] // 1 value
109
110 mov v27.s[2], v28.s[0]
111 mov v27.s[3], wzr
112
113 // B: COLUMN 0
114 ldr s29, [x8]
115
116 fmla v0.4s, v24.4s, v29.s[0]
117 fmla v1.4s, v25.4s, v29.s[0]
118 fmla v2.4s, v26.4s, v29.s[0]
119 fmla v3.4s, v27.4s, v29.s[0]
120 // B: COLUMN 1
121 add x8, x8, x4
122 ldr s29, [x8]
123 fmla v4.4s, v24.4s, v29.s[0]
124 fmla v5.4s, v25.4s, v29.s[0]
125 fmla v6.4s, v26.4s, v29.s[0]
126 fmla v7.4s, v27.4s, v29.s[0]
127 // B: COLUMN 2
128 add x8, x8, x4
129 ldr s29, [x8]
130 fmla v8.4s, v24.4s, v29.s[0]
131 fmla v9.4s, v25.4s, v29.s[0]
132 fmla v10.4s, v26.4s, v29.s[0]
133 fmla v11.4s, v27.4s, v29.s[0]
134 // B: COLUMN 3
135 add x8, x8, x4
136 ldr s29, [x8]
137 fmla v12.4s, v24.4s, v29.s[0]
138 fmla v13.4s, v25.4s, v29.s[0]
139 fmla v14.4s, v26.4s, v29.s[0]
140 fmla v15.4s, v27.4s, v29.s[0]
141 // B: COLUMN 4
142 add x8, x8, x4
143 ldr s29, [x8]
144 fmla v16.4s, v24.4s, v29.s[0]
145 fmla v17.4s, v25.4s, v29.s[0]
146 fmla v18.4s, v26.4s, v29.s[0]
147 fmla v19.4s, v27.4s, v29.s[0]
148 // B: COLUMN 5
149 add x8, x8, x4
150 ldr s29, [x8]
151 fmla v20.4s, v24.4s, v29.s[0]
152 fmla v21.4s, v25.4s, v29.s[0]
153 fmla v22.4s, v26.4s, v29.s[0]
154 fmla v23.4s, v27.4s, v29.s[0]
155
156 // move to next column of A
157 add x7, x7, x3
158 // move to next row of B
159 mov x8, x1
160 add x9, x9, #4
161 add x8, x8, x9
162
163 // decrement loop counter
164 sub x6, x6, #1
165 // check if loop counter is zero
166 cbnz x6, _k1_loop
In the third approach we again changed the load instructions from ldp to ld1.
ld1 loads 85_k1_loop:
86 // load column of A
87 ld1 {v24.4s-v26.4s}, [x7] // 12 values
88 ldr d27, [x7, #48] // 2 values
89 ldr s28, [x7, #56] // 1 value
90
91 mov v27.s[2], v28.s[0]
92 mov v27.s[3], wzr
93
94 // B: COLUMN 0
95 ldr s29, [x8]
96
97 fmla v0.4s, v24.4s, v29.s[0]
98 fmla v1.4s, v25.4s, v29.s[0]
99 fmla v2.4s, v26.4s, v29.s[0]
100 fmla v3.4s, v27.4s, v29.s[0]
101 // B: COLUMN 1
102 add x8, x8, x4
103 ldr s29, [x8]
104 fmla v4.4s, v24.4s, v29.s[0]
105 fmla v5.4s, v25.4s, v29.s[0]
106 fmla v6.4s, v26.4s, v29.s[0]
107 fmla v7.4s, v27.4s, v29.s[0]
108 // B: COLUMN 2
109 add x8, x8, x4
110 ldr s29, [x8]
111 fmla v8.4s, v24.4s, v29.s[0]
112 fmla v9.4s, v25.4s, v29.s[0]
113 fmla v10.4s, v26.4s, v29.s[0]
114 fmla v11.4s, v27.4s, v29.s[0]
115 // B: COLUMN 3
116 add x8, x8, x4
117 ldr s29, [x8]
118 fmla v12.4s, v24.4s, v29.s[0]
119 fmla v13.4s, v25.4s, v29.s[0]
120 fmla v14.4s, v26.4s, v29.s[0]
121 fmla v15.4s, v27.4s, v29.s[0]
122 // B: COLUMN 4
123 add x8, x8, x4
124 ldr s29, [x8]
125 fmla v16.4s, v24.4s, v29.s[0]
126 fmla v17.4s, v25.4s, v29.s[0]
127 fmla v18.4s, v26.4s, v29.s[0]
128 fmla v19.4s, v27.4s, v29.s[0]
129 // B: COLUMN 5
130 add x8, x8, x4
131 ldr s29, [x8]
132 fmla v20.4s, v24.4s, v29.s[0]
133 fmla v21.4s, v25.4s, v29.s[0]
134 fmla v22.4s, v26.4s, v29.s[0]
135 fmla v23.4s, v27.4s, v29.s[0]
136
137 // move to next column of A
138 add x7, x7, x3
139 // move to next row of B
140 mov x8, x1
141 add x9, x9, #4
142 add x8, x8, x9
143
144 // decrement loop counter
145 sub x6, x6, #1
146 // check if loop counter is zero
147 cbnz x6, _k1_loop
For these kernels we also executed benchmarks:
matmul_15_6_64 approaches41Benchmarking V1_Matmul_15_6_64 throughput ...
42-----------------------------------------------
43Measuring throughput for Instruction
44Total time (s): 2.57834
45Instructions per Second: 8.93599e+10
46Estimated GFLOPS: 89.3599 GFLOPS/sec
47-----------------------------------------------
48
49Benchmarking V2_Matmul_15_6_64 throughput ...
50-----------------------------------------------
51Measuring throughput for Instruction
52Total time (s): 2.1093
53Instructions per Second: 1.09231e+11
54Estimated GFLOPS: 109.231 GFLOPS/sec
55-----------------------------------------------
56
57Benchmarking V3_Matmul_15_6_64 throughput ...
58-----------------------------------------------
59Measuring throughput for Instruction
60Total time (s): 2.10837
61Instructions per Second: 1.09279e+11
62Estimated GFLOPS: 109.279 GFLOPS/sec
63-----------------------------------------------
Similar to the benchmarks for the matmul_14_6_64, the single loop approach significantly outperformed the two loop implementation. In this case, the difference was even bigger, with a gap of approximately 20 GFLOPs. However, unlike before, changing the load instruction from ldp to ld1 had no impact on the overall performance.
3.4.3 Generic Approach
As a proof of concept, we also implemented a generic matrix multiplication kernel capable of handling any M > 0. The core idea is to write specific kernels for M = 1, 2, ..., 8. For input sizes larger than M = 8, we then divide M by 8 (shift right by 3) and use that to loop the M = 8 kernel, which is basically a matmul_8_6_64 kernel. Any remaining elements (1 <= M % 8 <= 7) are handled by using on of the smaller specialized remainder kernels. To enable this dynamic selection, we employ a jump table that maps the remainder values to their respective kernel entry points.
We also benchmarked the performance of this generic kernel:
matmul_M_6_64 (M = 14) approach33Benchmarking Matmul_M_6_64 M=14 throughput ...
34-----------------------------------------------
35Measuring throughput for Instruction
36Total time (s): 2.32252
37Instructions per Second: 9.25891e+10
38Estimated GFLOPS: 92.5891 GFLOPS/sec
39-----------------------------------------------
matmul_M_6_64 (M = 15) approach65Benchmarking Matmul_M_6_64 M=15 throughput ...
66-----------------------------------------------
67Measuring throughput for Instruction
68Total time (s): 3.49118
69Instructions per Second: 6.59948e+10
70Estimated GFLOPS: 65.9948 GFLOPS/sec
71-----------------------------------------------
Compared to our best fixed-size implementations, the generic kernel shows a slightly lower performance, approximately 20 GFLOPs lower for M = 14, and around 45 GFLOPs lower for M = 15. This performance gap is expected due to the overhead of dynamic branching and the generalization of memory access patterns.
3.5 Accumulator Block Shapes
In this task, we were supposed to implement a microkernel that computes C+=AB for M=64, N=64 and K=64.
Starting from our previous matmul_64_48_64 kernel, we adapted the implementation to support N=64. Internally, this kernel relies on a smaller microkernel. In our previous version, we used matmul_16_6_64, which we replaced with matmul_16_4_64. Reducing N from 6 to 4 allows us to split the N dimension into 16 blocks of 4 columns. We found that using N=8 caused issues due to the limited number of available SIMD registers, which made register allocation and performance tuning more difficult.
Since this kernel is very similar to our earlier matmul_64_48_64 implementation, we chose to not include the code for this kernel here.
The benchmarking results for the new kernel are shown below:
matmul_64_64_64 approaches 1Benchmarking V1 Matmul throughput ...
2-----------------------------------------------
3Measuring throughput for Instruction
4Total time (s): 1.27442
5Instructions per Second: 1.23418e+11
6Estimated GFLOPS: 123.418 GFLOPS/sec
7-----------------------------------------------
8
9Benchmarking V2 Matmul throughput ...
10-----------------------------------------------
11Measuring throughput for Instruction
12Total time (s): 1.246
13Instructions per Second: 1.26233e+11
14Estimated GFLOPS: 126.233 GFLOPS/sec
15-----------------------------------------------
Version V1was directly derived from the matmul_64_48_64 kernel. Trying to improve its performance, we introduced minor optimizations to the stride calculations and removed unnecessary loads and stores of callee-saved registers that were not used. These adjustments led to a consistent performance improvement of 2-3 GFLOPs, resulting in version V2.
Below, we compare the naive and the optimized stride calculations:
39 // multiply strides with float size
40 mov x6, #4
41 mul x3, x3, x6 // lda
42 mul x4, x4, x6 // ldb
43 mul x5, x5, x6 // ldc
44
45 mov x6, #4
46 mul x22, x4, x6 // ldb * 4 columns
47 mul x23, x5, x6 // ldc * 4 columns
37 // multiply strides with float size
38 // *4 = lsl #2
39 lsl x3, x3, #2 // lda
40 lsl x4, x4, #2 // ldb
41 lsl x5, x5, #2 // ldc
42
43 lsl x22, x4, #2 // ldb * 4 columns
44 lsl x23, x5, #2 // ldc * 4 columns
3.6 Batch-Reduce GEMM
Based on the previous tasks, we now implement a batch-reduce GEMM (BRGEMM) kernel.
The goal is to implement a kernel that computes the operation \(C+=\sum_i A_i B_i\) for batched matrix inputs, with M=64, N=48, and K=64. The kernel should be able to handle batches of matrices. For now, we restrict the implementation to the case where the batch size is 16.
Similar to the previous tasks, we developed and benchmarked multiple versions of the kernel to optimize for performance.
In our first version we used our matmul_64_48_64 kernel from our loops section. We wrapped it inside a loop that runs 16 times, once for each matrix pair in the batch.
Two key aspects that we addressed were the following:
// Batch counter
mov x24, #16
_n_batch:
...
sub x24, x24, #1
cbnz x24, _n_batch
// END N BATCH
A and B in the batch230 // next A matrix
231 add x0, x0, x6 // A
232 mov x8, x0 // A
233
234 // next B matrix
235 add x1, x1, x7 // B
236 mov x20, x1 // B
237
238 // restore Pointer for matrix C
239 mov x21, x2 // C
240 mov x10, x21 // C
241
242 sub x24, x24, #1
243
244 cbnz x24, _n_batch
In our second version, we applied some optimizations to the kernel. The changes we made were:
MUL’s with LSL’s39 // multiply strides with float size
40 lsl x3, x3, #2 // lda in bytes
41 lsl x4, x4, #2 // ldb in bytes
42 lsl x5, x5, #2 // ldc in bytes
43 lsl x6, x6, #2 // br_stride_a in bytes
44 lsl x7, x7, #2 // br_stride_b in bytes
LDP’s with LD1’s and STP’s with ST1’s78 // LOAD MATRIX C
79 mov x12, x10
80 // first column
81 ld1 {v0.4s, v1.4s, v2.4s, v3.4s}, [x12]
82 // second column
83 add x12, x12, x5
84 ld1 {v4.4s, v5.4s, v6.4s, v7.4s}, [x12]
85 // third column
86 add x12, x12, x5
87 ld1 {v8.4s, v9.4s, v10.4s, v11.4s}, [x12]
88 // fourth column
89 add x12, x12, x5
90 ld1 {v12.4s, v13.4s, v14.4s, v15.4s}, [x12]
91 // fifth column
92 add x12, x12, x5
93 ld1 {v16.4s, v17.4s, v18.4s, v19.4s}, [x12]
94 // sixth column
95 add x12, x12, x5
96 ld1 {v20.4s, v21.4s, v22.4s, v23.4s}, [x12]
These optimizations resulted in a performance improvement of about 3-4 GFLOPs.
1Benchmarking V1_Matmul_64_48_64_16 throughput ...
2-----------------------------------------------
3Measuring throughput for Instruction
4Total time (s): 1.22446
5Instructions per Second: 1.28453e+11
6Estimated GFLOPS: 128.453 GFLOPS/sec
7-----------------------------------------------
8
9Benchmarking V2_Matmul_64_48_64_16 throughput ...
10-----------------------------------------------
11Measuring throughput for Instruction
12Total time (s): 1.19946
13Instructions per Second: 1.31131e+11
14Estimated GFLOPS: 131.131 GFLOPS/sec
3.7 Transposition
In this task, we explored how to transpose an 8x8 matrix using Neon assembly instructions. Our approach was to first develop a solution for the simpler 4x4 case.
3.7.1 Transposition Implementation
To begin, we loaded all 4 columns of matrix A using ldr qX, [x0], so that the entire matrix is placed in our registers. The second step would be to transpose the matrix:
trans_4_4 implementation56 /*
57 * Part 2.1:
58 * Transpose 4x4 block.
59 */
60 trn1 v4.4s, v0.4s, v2.4s
61 trn1 v5.4s, v1.4s, v3.4s
62
63 trn2 v6.4s, v0.4s, v2.4s
64 trn2 v7.4s, v1.4s, v3.4s
65
66 /*
67 * Part 2.2:
68 * Transpose 4x4 block.
69 */
70 zip1 v8.4s, v4.4s, v5.4s // B "column" 0
71 zip1 v9.4s, v6.4s, v7.4s // B "column" 1
72
73 zip2 v10.4s, v4.4s, v5.4s // B "column" 2
74 zip2 v11.4s, v6.4s, v7.4s // B "column" 3
The idea of trn1 and trn2 is to prepare the elements for each column, so that
we can then leverage their new structure using zip1 and zip2.
To scale this to an 8x8 matrix, we divided the matrix into four 4x4 submatrices:
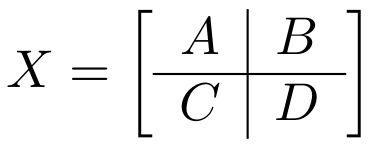
Each quadrant was transposed independently using our trans_4_4 kernel:
The upper-left matrix (in the image A) was transposed and stored at the same position.
The upper-right matrix (in the image B) was transposed and stored into the position originally occupied by the bottom-left matrix.
The bottom-left matrix (in the image C) would be transposed and stored into the position originally occupied by the upper-right matrix.
The bottom-right matrix (in the image D) was transposed and stored at the same position.
89 /*
90 * Part 1.2:
91 * Load 4x4 block of A (Left bottom, top right).
92 */
93 mov x4, x0 // A
94 mov x5, x1 // B
95
96 add x4, x4, #16
97 add x5, x5, #16
98
99 ldr q0, [x4]
100 add x4, x4, x2
101 ldr q1, [x4]
102 add x4, x4, x2
103 ldr q2, [x4]
104 add x4, x4, x2
105 ldr q3, [x4]
106
107 // Right top
108 mov x4, x0 // A
109 mov x5, x1 // B
110
111 add x4, x4, #128
112 add x5, x5, #128
113
114 ldr q12, [x4]
115 add x4, x4, x2
116 ldr q13, [x4]
117 add x4, x4, x2
118 ldr q14, [x4]
119 add x4, x4, x2
120 ldr q15, [x4]
121
122 /*
123 * Part 2.1:
124 * Transpose 4x4 block.
125 */
126 // Left Bottom
127 trn1 v4.4s, v0.4s, v2.4s
128 trn1 v5.4s, v1.4s, v3.4s
129
130 trn2 v6.4s, v0.4s, v2.4s
131 trn2 v7.4s, v1.4s, v3.4s
132
133 // Right Top
134 trn1 v16.4s, v12.4s, v14.4s
135 trn1 v17.4s, v13.4s, v15.4s
136
137 trn2 v18.4s, v12.4s, v14.4s
138 trn2 v19.4s, v13.4s, v15.4s
139
140 /*
141 * Part 2.2:
142 * Transpose 4x4 block.
143 */
144 // Left Bottom
145 zip1 v8.4s, v4.4s, v5.4s
146 zip1 v9.4s, v6.4s, v7.4s
147
148 zip2 v10.4s, v4.4s, v5.4s
149 zip2 v11.4s, v6.4s, v7.4s
150
151 // Right Top
152 zip1 v20.4s, v16.4s, v17.4s
153 zip1 v21.4s, v18.4s, v19.4s
154
155 zip2 v22.4s, v16.4s, v17.4s
156 zip2 v23.4s, v18.4s, v19.4s
157
158 /*
159 * Part 3:
160 * Store 4x4 block of Submatrix A''' into A''.
161 */
162 // Left Bottom (values from right top)
163 mov x5, x1
164 add x5, x5, #16
165
166 str q20, [x5]
167 add x5, x5, x3
168 str q21, [x5]
169 add x5, x5, x3
170 str q22, [x5]
171 add x5, x5, x3
172 str q23, [x5]
173
174 // Right top (values from left bottom)
175 mov x5, x1
176 add x5, x5, #128
177
178 str q8, [x5]
179 add x5, x5, x3
180 str q9, [x5]
181 add x5, x5, x3
182 str q10, [x5]
183 add x5, x5, x3
184 str q11, [x5]
To optimize our initial implementation, we removed the PCS for all regsiters that we didn’t use. We also restructured our code for clarity and compactness.
40 mov x9, #2 // n loop
41
42n_loop:
43
44 mov x6, #2 // m loop
45
46m_loop:
47 /*
48 * Part 1:
49 * Transpose 4x4 block.
50 */
51 mov x7, x4
52 mov x8, x5
53
54 ldr q0, [x7]
55 add x7, x7, x2
56
57 ldr q1, [x7]
58 add x7, x7, x2
59
60 ldr q2, [x7]
61 add x7, x7, x2
62
63 ldr q3, [x7]
64
65 /*
66 * Part 2.1:
67 * Transpose 4x4 block.
68 */
69 trn1 v4.4s, v0.4s, v2.4s
70 trn1 v5.4s, v1.4s, v3.4s
71
72 trn2 v6.4s, v0.4s, v2.4s
73 trn2 v7.4s, v1.4s, v3.4s
74
75 /*
76 * Part 2.2:
77 * Transpose 4x4 block.
78 */
79 zip1 v16.4s, v4.4s, v5.4s
80 zip1 v17.4s, v6.4s, v7.4s
81
82 zip2 v18.4s, v4.4s, v5.4s
83 zip2 v19.4s, v6.4s, v7.4s
84
85 /*
86 * Part 3:
87 * Store 4x4 block of A into B.
88 */
89 str q16, [x8]
90 add x8, x8, x3
91
92 str q17, [x8]
93 add x8, x8, x3
94
95 str q18, [x8]
96 add x8, x8, x3
97
98 str q19, [x8]
99
100 // Jump 4 rows in A
101 add x4, x4, x25
102
103 // Jump 4 columns in B
104 add x5, x5, x27
105
106 sub x6, x6, #1
107 cbnz x6, m_loop
108
109
110 // Restore Pointer for A and B
111 mov x4, x0
112 mov x5, x1
113
114 add x12, x12, x26
115 add x13, x13, x25
116
117 add x4, x4, x12
118 add x5, x5, x13
119
120 sub x9, x9, #1
121 cbnz x9, n_loop
3.7.2 Performance Measuring
We measured the throughput of our transposition kernel in terms of memory transfer speed, since the core performance factor in this case is loading and storing elements efficiently.
trans_8_8 performance in GiB/s 1Benchmarking trans_neon_8_8 performance ...
2-----------------------------------------------
3Measuring throughput for transposition in GiB/s
4Total time (s): 1.26545
5Data movements per Second: 8.09199e+10
6Estimated GiB/s: 80.9199 GiB/s
7-----------------------------------------------
8
9Benchmarking v2_trans_neon_8_8 performance ...
10-----------------------------------------------
11Measuring throughput for transposition in GiB/s
12Total time (s): 0.902975
13Data movements per Second: 1.13403e+11
14Estimated GiB/s: 113.403 GiB/s
15-----------------------------------------------
Our benchmarking results show that the initial version achieved approximately 81 GiB/s. With our optimizations, we increased this to about 113 GiB/s.